Victor van Katwijk (victor@geodan.nl)
and Wideke Boersma (w.boersma@bunnik.cso.nl)
Geodan IT bv
Jan Luijkenstraat 10, 1071 CM Amsterdam
tel. +31(0)20 5707300, fax. +31(0)20
5707333
Introduction
Dealing with the integration of multiple sources of geographic information is an essential part of a methodology for establishing a land use database. The classification of satellite data alone is often not sufficient for mapping the environment. This certainly applies to the classification of NOAA-AVHRR data. The classification of remotely sensed satellite imagery for thematic mapping applications can be improved by the use of ancillary geographic information.
In the EC funded PELCOM project (see inset), a methodology is being established for creating a European Land Use database for environmental modelling. An essential part of this methodology is a tool/method for integrating multiple sources of land use information with the information resulting from the classification of remote sensing imagery.
Spatial data in a GIS have been shown to improve classification accuracy and aid in the extraction of information from remotely sensed imagery (Jansen 1994, Bolstad and Lillesand, 1992). In the context of the PELCOM project a preliminary literature study of methods for integrating satellite imagery and ancillary data is being done. Methods include incorporation of ancillary data before, during, or after a classification.
In the Land Use Integrator (LUI) the purpose of the methodology is to use and include the additional knowledge in the information extraction process. The aim of the method is to include knowledge of the thematic content of the information layers as opposed to the use of a priori knowledge on spatial characteristics as is done in other projects such as the CAMOTIUS project.
It has been found in the previous Land Use projects that there are numerous sources of ancillary land use information. These sources can have different thematic content with different relationships to the desired land use categories. In addition, the reliability of these sources will vary, and even within a data set the classes may have different reliabilities. It is also important to note that the analysis of remote sensing imagery can provide different types of information depending on the method used.
With a LUI (Land Use Integrator) the
information from various analyses techniques can be combined with the ancillary
geographic information to provide the best possible land use data set.
Methodology
The main objective of the Land Use Integrator is to combine data sets with geographic land use information as efficiently as possible, into a desired land use data set. In the methodology proposed the fuzzy knowledge about data sets and classes and the meaning of these data sets and classes to the actual land use at a location, is converted into relationships with probabilities and reliabilities. By bringing all the information and knowledge together simultaneously, the loss of information in the data is minimized and further enhanced by capturing the knowledge of classes etc.. The methodology to be used for integrating different data sets will be flexible, making it possible to add or remove data sets in the future.
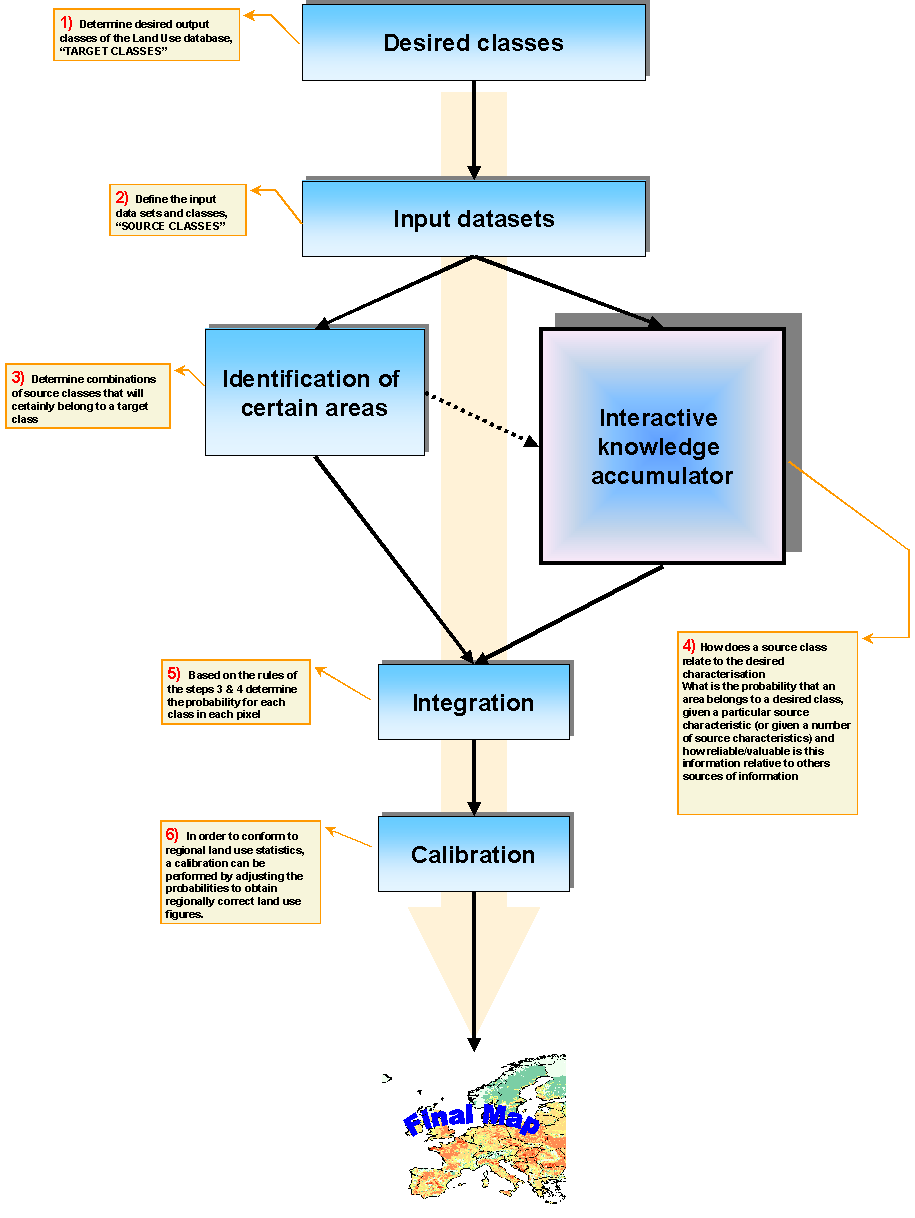
The data integration is performed in six steps, as can be seen in the flowchart.
1) Desired Classes
At first, the desired output classes of the Land Use database will be determined. These desired output classes are called "TARGET CLASSES".
2) Input datasets
The second step is to define the input data sets and classes, the so called "SOURCE CLASSES". If a data set is added the LUI automatically searches for the existing source classes and the frequency of occurrence of these classes.
3) Identification of certain areas
In this step the pixels for which the land use/ land cover class (target class) are almost 100% certain are identified. If a pixel has the same source class value, for example forest, in different data sets one can assume the target class in that pixel actually is forest. These pixels will not be changed in the next step of the data integration. The target classes in these pixels will be considered as locked. It could be considered, in a later stage, to change certain pixels into pixels with a high degree of probability that may be influenced by other information if the current method proofs to be too rigid.
4) Interactive knowledge accumulator
The fourth step is the most important step in the LUI. In this step the question will be answered: "How does a source class relate to the desired characterization".
What is the probability that an area belongs to a desired target class, given a particular source characteristic (or given a combination of source characteristics) and how reliable/valuable is this information relative to others sources of information. A matrix will be generated for each LU target class where for each combination of a source class and a data set the probability of this LU-class/data set/source-class combination must be indicated (probability matrix).
The probabilities indicated for the different sources will have a different reliability. For each source data set the relative reliability must be indicated. For example, one data set may be twice as reliable as another data set etc. In addition, it is likely that a certain source has classes that do not have the same reliability. When looking at the forest LU class, the forest class (e.g. in ESA) may, for instance, have a higher reliability than the urban class. For all combinations, this class reliability may be important, it can therefore be input in the so-called reliability matrix.
5) Integration
Based on the rules of the steps 3 & 4 the probability for each target class in each pixel will be determined. In this step, other sources with probabilistic information can be included. From these, a resulting land use map can be made using a maximum likelihood classification.
6) Calibration
A prerequisite of the resulting data
set can be that the regional class areas comply with the existing statistical
areas. For instance if the land use data set will be used for environmental
models influencing national and European political decisions it is important
that the regional figures match the statistical information. For this reason,
the methodology will include a procedure for adjusting the land use classification
to match the statistical values. By integrating several data sets into
one land use/land cover database, the quality of the result will exceed
the reliability of the separate data sets. The integrated land use/land
cover database will be used for monitoring land use on European level.
Implementation
Design
The LUI will be implemented in a "Three-tiered" software environment. The three components consist of a
1) user interface (PC),
2) model (Unix/PC)
3) database (Unix/PC)
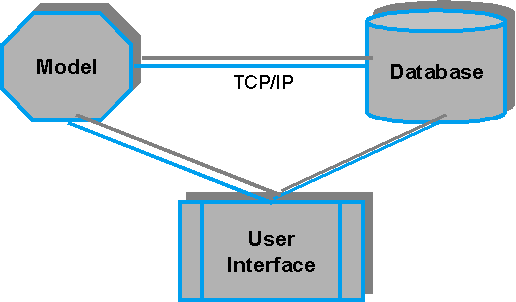
User interface
The user interface assists the user through the steps listed on the left. It will be PC-windows based and developed in Delphi.
Model
The model can be located on a different machine (Unix-platform or PC). Based on the specified probabilities and reliabilities, the model will do a per pixel computation of the probability of each of the target classes.
Database
The LUI database contains the source geographic data sets as well as the resulting data sets. An important aspect of the LUI is also that the decisions (the specified probabilities and the reliabilities) that are made to arrive at a particular data set are all captured in the LUI database. These logs make the process repeatable and give control over the whole process.
Communication
The user interface will communicate using TCP/IP with the model and the data. The model command centre will be operated through the user interface. Using this approach, each component can be changed independently of the other component.
Software
The software will be developed according
to the Geodan IT software specification, using Delphi and Geolib. Geolib
is the geographic software library/toolbox (C++) developed by Geodan IT.
Discussion
It should be realized that the integration of information from the classification often needs further interpretation and information from other sources before land use can be reliably determined. It is to be
expected that the procedures developed for integrating ancillary data will proof to be useful during the classification process also.